
Distant Reading: analyzing the Gospels with Python and AI
In Digital Humanities, distant reading uses computational tools to explore patterns across texts - patterns that may be difficult to perceive through close reading alone. Instead of replacing traditional interpretation, it complements it by providing statistical overviews that highlight tendencies, repetitions, and contrasts.
The Methodology, AI chatbots or Coding environment?
One could simply ask a chatbot, "Which Gospel is the most positive? "Which Gospel has the richest vocabulary?", and you might get compelling answers. Most AI chatbots have access to the Gospels and can perform statistical analysis of the texts directly. However, a big drawback with using AI chatbots is that the results usually lack scientific transparency. To perform a controlled and transparent analysis, we used Google Colab, a cloud-based coding environment. The four Gospels were downloaded in txt format in Google Drive so they could be accessed and treated in Google Colab with Python code. The python code was generated by AI chatbots (Gemeni and ChatGPT) and copied and pasted (sometimes lightly edited) in Google Colab, where the code was executed and the results displayed. This is a great and easy hybrid approach to using AI in a controlled and transparent way.
Visualizing Sentiment: The "Top 20" Word Clouds
One task was to perform a Sentiment Analysis using the VADER lexicon on the King James Version of the bible. By using Python, we maintained full control over the dictionary of emotions, and we filtered the results to show only the 20 most frequent sentiment-bearing words of each Gospel.

Matthew and Luke provide a balanced mix of moral and spiritual language, such as heaven, good, and blessed. The most striking contrast appears between Mark and John. Mark presents a "crisis narrative," where the sentiment cloud is more dramatic and action-driven, with terms like cried, astonished and devil. In John, the cloud centers instead on a high-frequency set of more positive core concepts, such as believe, love, and truth.
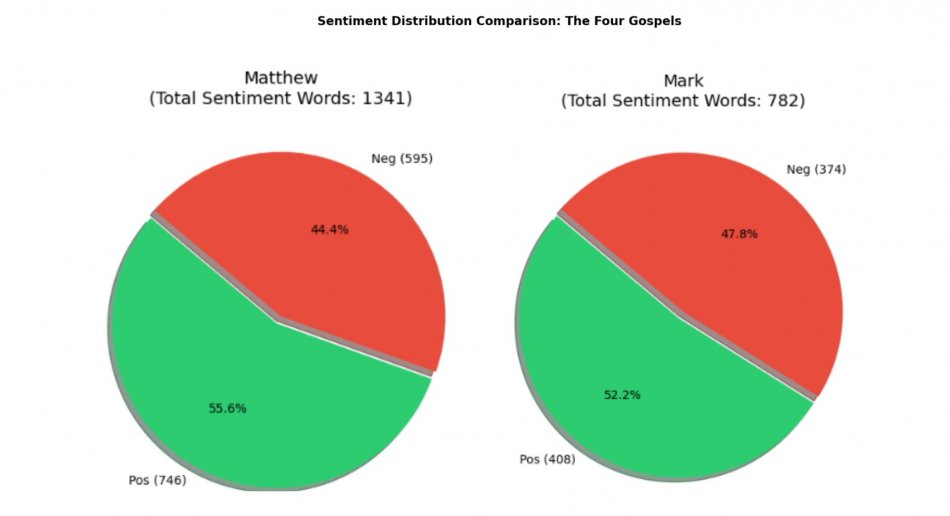
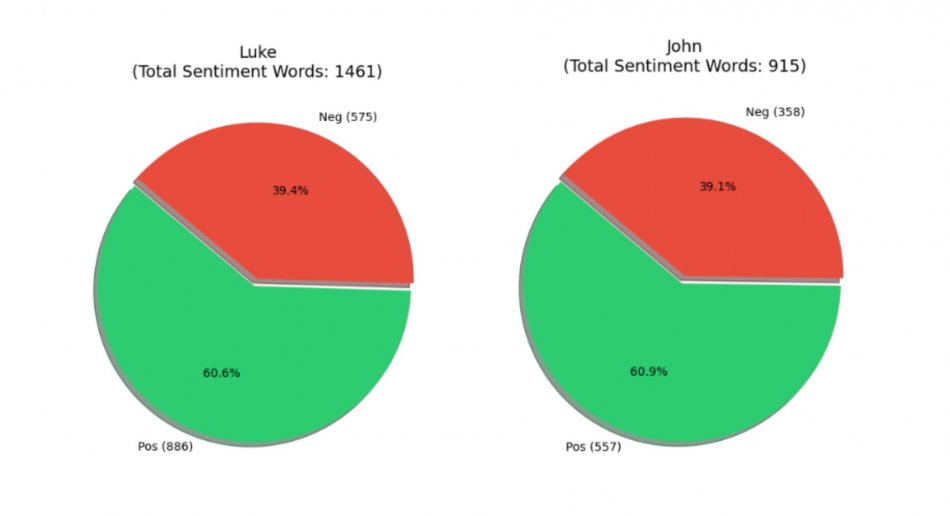
Quantitative Findings: Positive vs. Negative Distribution
When we aggregate all the sentiment words into a distribution, we can measure the "mood" of a corpus. Using a batch-processing script, we generated pie charts to compare the four narratives.
While all four gospels are mostly positive, some are more negative than others. Mark (47,8%), for instance, shows a larger negative distribution than John (39,1%), indicating his focus on the crisis and suffering of the narrative.
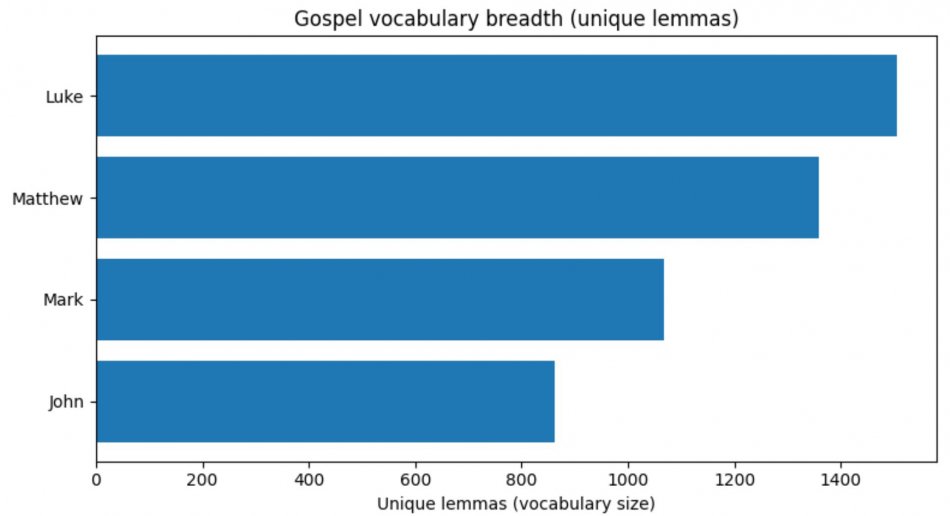
The vocabulary of the Gospels
To explore vocabulary size across the four Gospels, we treated each text as a corpus and measured lexical diversity computationally. After removing stopwords (such as "the”), lemmatizing words (so “say” and “says” count as the same word), and excluding proper names, we calculated two related but distinct measures. First, we counted the number of unique lemmas in each Gospel, which gives a sense of overall vocabulary breadth. Second, we calculated the Moving-Average Type–Token Ratio (MATTR), a length-sensitive measure of lexical diversity that reduces the bias introduced by longer texts naturally accumulating more unique words. The first bar chart shows which Gospel uses the largest number of different word forms overall; the second shows which Gospel is lexically most diverse relative to its length.
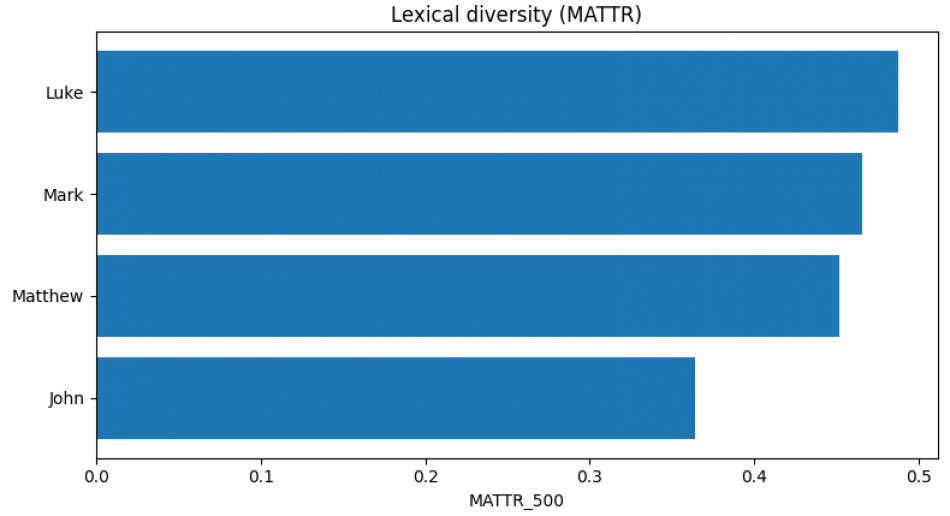
Methods over Findings
It is important to note that these results are methodological demonstrations rather than definitive theological claims based on rigorous scientific research. Technical details regarding the methods, especially the sentiment lexicon and Python parameters, were omitted for length but can be provided to anyone interested in the full methodology.
Get Involved at the Lab
Whether you are interested in the Four Gospels or a completely different corpus, the L-MASDR lab is here to assist with Distant Reading and AI-assisted coding.
AI use declaration
This blog post was drafted with AI assistance to help structure the narrative and synthesize the coding processes used in this project. The Python scripts used for this analysis were co-developed with Gemini Pluss and ChatGPT Team 5.2. The cover picture was made with Gemeni.
More articles from MF L-MaSDR, AI, Digital humanities, Distant reading and Gospels
Using AI Agents to Prototype a Manuscript VRE
Published: 25. June 2026
This post presents an experiment in AI-assisted digital humanities development. Using Claude Code, I built a local prototype of a Virtual Research Environment (VRE) for the study of Tatian’s Diatessaron. The purpose was to test whether AI-assisted coding can help transform manuscript data, research notes, and a conceptual model into a working tool for visualization, collation, and textual comparison.

Artificial Intelligence and the Humanities: New Opportunities and Challenges
Published: 18. February 2026
In December 2025, L-MaSDR hosted a seminar exploring the opportunities, challenges, and responsibilities that AI presents for humanistic research. Watch the presentations here.

A Visit to Juma Al Majid Center for Culture and Heritage
Published: 29. January 2026
During a two-week research stay in the United Arab Emirates, sponsored by the NYU Abu Dhabi Humanities Research Fellowships, the director of MF L-MaSDR had the opportunity to engage with several pioneering institutions.
Transcribing Old Manuscripts with AI: Transkribus or Chatbots?
Published: 12. December 2025
Should researchers rely on specialised platforms like Transkribus to transcribe old manuscripts, or can general AI chatbots do the job just as well? In this post, I share my experiences testing both approaches on a medieval Latin manuscript.