Transcribing Old Manuscripts with AI: Transkribus or Chatbots?
Should researchers rely on specialised platforms like Transkribus to transcribe old manuscripts, or can general AI chatbots do the job just as well? In this post, I share my experiences testing both approaches on a medieval Latin manuscript.
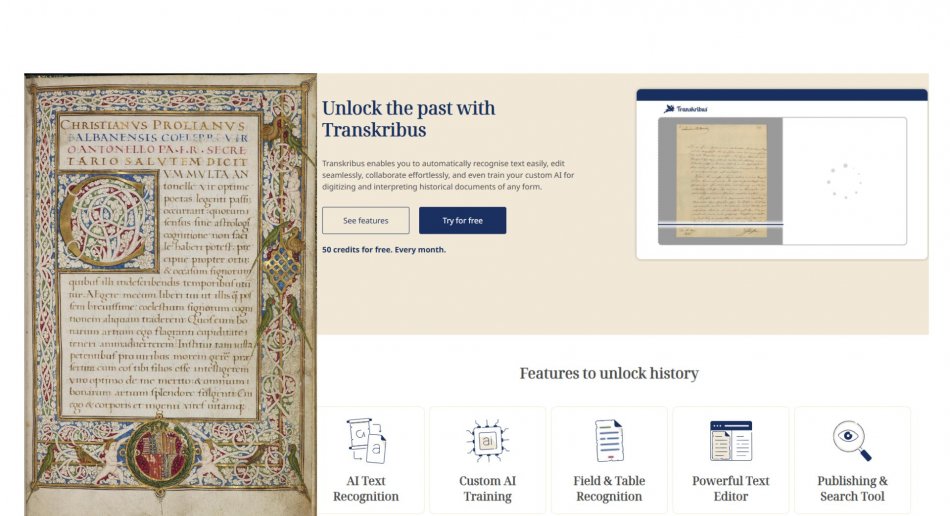
Transkribus – unlocking the past with AI
Transkribus is an AI-powered platform specifically designed for transcribing historical documents and manuscripts. It uses handwritten text recognition (HTR) technology to automatically read and transcribe old handwriting - including challenging scripts like medieval Latin, Gothic, or early modern hands. The platform allows you to train custom AI models on your specific manuscript collection, meaning it learns to recognize the particular handwriting styles, abbreviations, and paleographic conventions common in your materials. Once trained, it can transcribe pages in minutes that would take hours by hand.
The free version starts with 50 credits = 50 pages. It gives you access to hundreds of models in different languages and time periods, but Transkribus’ Super Models only come with paid subscription. The free version is therefore only a viable option for testing and small scale transcriptions.
The key to achieving high-accuracy transcription lies in selecting the right HTR model for your specific material. Match the four factors:
1. Language
2. Script/Handwriting Style
3. Time Period (Century)
4. Content Type
Research and other sources comparing Transkribus, ChatGPT, Gemeni and Claude AI
Transkribus themselves claim great superiority, 3.5x more accurate in handwriting, over LMM’s in this blog post.
However, in this research article Crosilla, Klic, and Colavizza (2025) write that LLMs in some cases compete with Transkribus:
While LLMs achieved comparable results for English historical handwriting and outperformed Transkribus on modern handwriting and Italian datasets, Transkribus models showed better results on German and multilingual datasets. Platforms like Transkribus and general LLMs will likely continue to coexist as tools supporting users’ activities, each being selected based on specific needs [...]. At the moment, for tasks requiring highly tailored solutions, Transkribus’ user interface and specialized models remain advantageous (Crosilla et al., 2025).
According to Huggingfaces language benchmark for LLMs in Latin, Claude beats Gemeni and ChatGPT.
Manuscript and prompt
Title: Astronomia,
Author(s): Prolianus, Christianus, 15th century, Latin
source: https://www.digitalcollections.manchester.ac.uk/view/MS-LATIN-00053/5
Prompt:
transcribe this photo. metadata: Physical Location: The John Rylands Library Collection: Latin Manuscripts Classmark: Latin MS 53 Title: Astronomia Language(s): Latin Subject(s): Astronomy Author(s): Prolianus, Christianus, 15th century Origin Place: Naples Date of Creation: 1470-1480 Former Owner(s): Lindsay, James Ludovic, 1847-1913; Quaritch, Bernard, 1819-1899 Associated Person(s): Gigantibus de Rottenburg, Gioacchino de, 1453-1485; Morris, William, 1834-1896 Format: Codex Material(s): Parchment Extent: ff. 79 (i+77+i) Leaf height: 212 mm, width: 140 mm.
Disclaimer: I don’t read Latin, and I do not know the correct full transcription, but I have partly relied on a blog called prolianusastrologia that translates parts of the text, and I have relied on my own visual interpretation and investigation. You may judge for yourself, especially if you know Latin, comparing the manuscript from the University of Manchester to the transcriptions at the bottom of this page.
Test results
The Transkribus Print M1 model is trained on printed text, which does not match the handwritten manuscript. Nevertheless, this worked best of all the Latin models I tested in Transkribus. Still, it did not perform comparatively well. Especially towards the end, it simply left out several words that the other three models included correctly; like the last word signorum. Apart from that, it was not that far behind the LLMs, and it was the only model that got the word Balbanensis completely right.
Claude is the only model that occasionally puts [...] when it does not know the answer. This is a humble and trustworthy trait, implying that it is not as keen on inventing answers and hallucinating. This aligns with its reputation for being a more ethical and sober model. However, all the other models got it right for one of those instances, and Gemeni got both right (PA F.R. and Coelebri), indicating a slightly lower accuracy from Claude.
Only Gemeni got the authors’ name Christianus completely right, with a U instead of a V. All four had different answers for word nr. 4: Coeleprevar, Coelesp, Coelepp[...] and Coelebre (Gemeni). The latter seems to be the closest and most plausible interpretation both visually and semantically. The blog resource transcribed it as coelebri, which is closest to Gemeni’s Coelebre.
Another disagreement is on the line: le haberi po*. Based on my visual interpretation, the right word is le haberi potest, and only Claude gets that right. The others said possit (ChatGPT) and poterit (Gemeni).
Conclusion
The differences in accuracy between the LLMs in this test are not very big, but I would say Gemeni proved a slight advantage, while Transkribus clearly produced the weakest results. However, that does not mean that LLMs beat Transkribus in all cases. Transkribus’ strength is to train very specific models that are accurate and superior to LLMs on marginal languages, complicated and feeble materials. This test did not fully prove such a case, and it did not use its Super Models either. Still, this test suggests that LLMs can be a usefull and easy access tool that can support Transkribus for transcribing old manuscripts.
Other machine-assisted transcription services
NorHand: a free and open model by the Norwegian National Library trained on Norwegian handwriting from 1820-1940:
https://app.transkribus.org/models/public/text/norhand_v0-7
For more models by the National Library, including a Sami model:
https://www.nb.no/dh-lab/handskrifter/
The models’ transcriptions (only half a page for brevity):
Transkribus Print M1:
CHRISTIANVS PROLIANVS
BALBANENSIS COELEPREVAR
OANTONELLO PA-F.R. SECRE
TARIO SALVTEM DICII
VMMVLTAAN
tonelle Vir optime-
poetas legenti passi;
occurrant: quorumi
sensus sinc astrologi
coonitione
le haberi po
cipue propt
& occasum si¬
ChatGPT(Team, 5.1):
CHRISTIANVS PROLIANVS
DALBANENSIS COELESP. EP. VIR
O ANTONELLO PA. F. R. SECRE-
TARIO SALVTEM DICIT
VM MVLTA AN-
tonelle vir optime
poetas legenti passim
occurrant quorum sen-
sus sine astrologi-
cognitione non faci-
le haberi possit, prae-
cipue propter ortu-
s & occasum signorum
Gemeni (Pluss, 3 Pro):
CHRISTIANUS PROLIANVS
ALBANENSIS COELEBRE VIR
O ANTONELLO PA * F * R *
SECRETARIO SALVTEM DICIT
V M MVLTA AN
tonelle vir optime
poetas legenti passis
occurrant * quorum * i
sensus sine astrologi
cognitione non facile
haberi poterit *
precipue propter ortu
** & occasum signorum
Claude (sonnet 4.5):
Header (in gold and red capitals):
CHRISTIANVS PROLIANVS
ALBANENSIS COELEPP[...] VIR
O ANTONELLO PA[...]R · SECRE
TARIO SALVTEM DICIT
Main text:
VM MVLTA AN
tonelle vir optime
poetas legenti passi
occurrant : quorum
sensus sine astrologi
cognitione non faci
le haberi potest: pre
cipue propter ortu
& occasum signorum
AI use declaration
ChatGPT 5.1 was used when producing parts of the paragraph introducing Transkribus. Throughout the article ChatGPT was occasionally used to improve the language.
More articles from MF L-MaSDR, l-msdr, Digital humanities, digital humaniora, transcription, AI, KI, manuscripts and transkripsjon
Using AI Agents to Prototype a Manuscript VRE
Published: 25. June 2026
This post presents an experiment in AI-assisted digital humanities development. Using Claude Code, I built a local prototype of a Virtual Research Environment (VRE) for the study of Tatian’s Diatessaron. The purpose was to test whether AI-assisted coding can help transform manuscript data, research notes, and a conceptual model into a working tool for visualization, collation, and textual comparison.

Distant Reading: analyzing the Gospels with Python and AI
Published: 19. February 2026
In Digital Humanities, distant reading uses computational tools to explore patterns across texts - patterns that may be difficult to perceive through close reading alone. Instead of replacing traditional interpretation, it complements it by providing statistical overviews that highlight tendencies, repetitions, and contrasts.

Artificial Intelligence and the Humanities: New Opportunities and Challenges
Published: 18. February 2026
In December 2025, L-MaSDR hosted a seminar exploring the opportunities, challenges, and responsibilities that AI presents for humanistic research. Watch the presentations here.

A Visit to Juma Al Majid Center for Culture and Heritage
Published: 29. January 2026
During a two-week research stay in the United Arab Emirates, sponsored by the NYU Abu Dhabi Humanities Research Fellowships, the director of MF L-MaSDR had the opportunity to engage with several pioneering institutions.